

こんにちは、柳ヶ瀬です。
今回はUUIDv4の仕組みと、どの程度の確率で衝突するのかを整理していきます。
UUIDは「ほぼ一意」として広く使われていますが、もちろん数学的には衝突確率がゼロではありません。
ただし、ここで大事なのは「UUIDv4そのものの理論上の衝突確率」と「実際のシステムで理論より早く衝突して見える技術的な原因」を分けて考えることです。
後半では、誕生日のパラドックスを使って衝突確率を計算しつつ、
実務で気を付けたい乱数実装やライブラリ選定の話まで見ていきましょう!
UUIDv4とは?
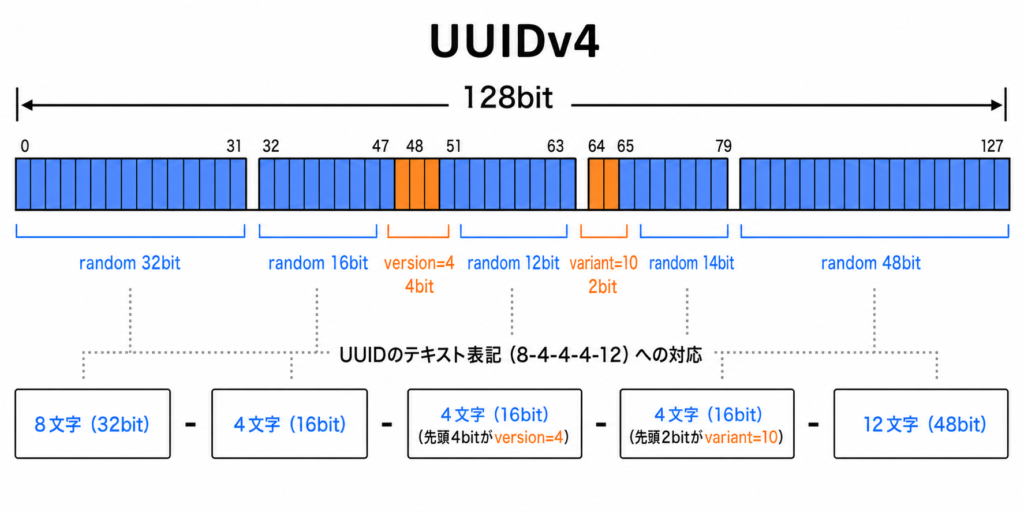
UUIDは128bitの識別子です。
そのうちUUIDv4は、ランダム値をベースに生成されるバージョンとしてよく使われています。
例えばこのような形式ですね。
550e8400-e29b-41d4-a716-446655440000ただし128bitすべてが完全に自由な乱数というわけではありません。
UUIDv4ではversionとvariantを表すビットが固定されるため、
実際にランダムとして使えるのは122bitです。
つまり、UUIDv4の候補数は
となります。
10進数で書くととんでもない桁数ですね。
約 通りあるので、普通に使う限りはまず重複しなさそうに見えます。
UUIDv4はなぜ衝突しにくいのか
1個のUUIDだけを見ると、取り得る値が 通りもあるので、
すでに存在するUUIDとぴったり一致する可能性は極端に低いです。
しかし、UUIDを大量に発行していくと話が変わります。
これは「誕生日のパラドックス」と同じで、全員が同じ誕生日になる確率ではなく、
誰かと誰かが一致してしまう確率を考える必要があるからです。
人数が増えるほど比較する組み合わせ数が急激に増えるため、
見た目以上に早く「どこかで一致する可能性」が上がっていきます。
誕生日のパラドックスで衝突確率を計算する
UUIDv4のランダム空間を とします。
ここでいきなり衝突確率を考えると少し分かりづらいので、
まずは「個すべてが重複しない確率」を考えます。
1個目は必ず未使用なので確率は 1
2個目は1個目と被らないので
3個目は前の2個と被らないので です。
これを続けると、重複しない確率は
と書けます。そして、
求めたいのは「少なくとも1回は衝突する確率」なので、補集合を使って
となります。この積の形のままだと扱いづらいので、
誕生日のパラドックスではここを指数関数で近似することが多いです。
その結果、 個のUUIDを生成して1つ以上の衝突が起きる確率は、近似的に次の式で表せます。
これは誕生日のパラドックスでよく出てくる式ですね。
直感的な説明としては、BetterExplainedの解説 がかなり分かりやすいです。
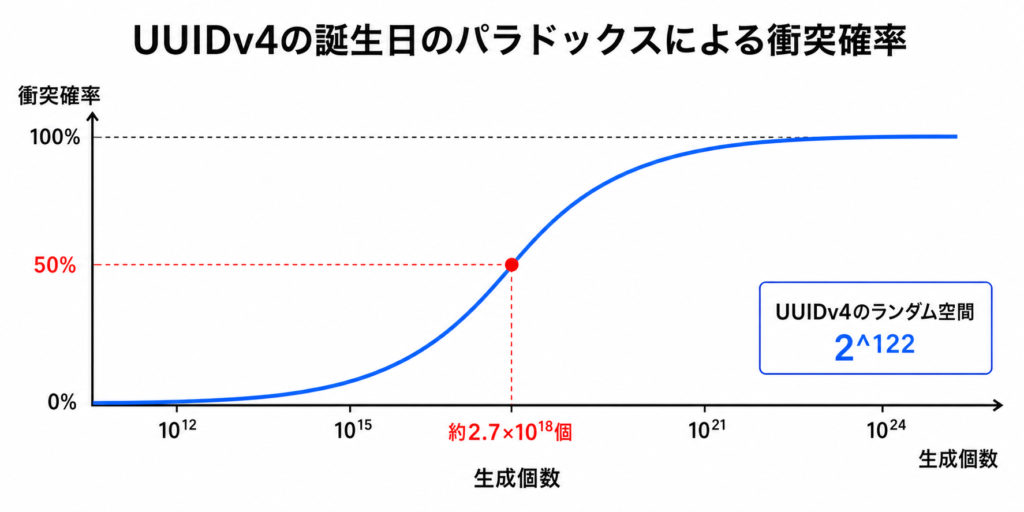
衝突確率が50%を超える生成個数の目安
UUIDを 個生成したときに、1個以上衝突している確率が50%となるkを求めてみましょう。
として解くと、
となるので、UUIDv4では
個あたりで、衝突確率が約50%になります。
おおよそ27京個 です。
かなり途方もない数字ですね。
最初の衝突が起きる期待値
「50%で衝突する個数」と「最初の衝突が起きる期待値」は少し違います。
期待値で見ると、初回衝突までの生成回数はおおよそ
で近似でき、UUIDv4では
回程度になります。こちらもやはり、現実的なシステムではほぼ天文学的な数字です。
どれくらい現実離れしているか
50%衝突地点の 個をベースに、
毎秒どれだけUUIDを発行すると到達するかをざっくり見てみます。
| UUIDv4の発行速度 | 50%衝突確率に達するまでの目安 |
|---|---|
| 毎秒1万個 | 約860万年 |
| 毎秒100万個 | 約8.6万年 |
| 毎秒10億個 | 約86年 |
毎秒10億個というかなり極端な速度でも、なお約86年です。
ですので、正しく実装されたUUIDv4が理論通りの122bitランダム性を持っているなら、通常の業務システムで衝突を心配する場面はほとんどありません。
ちなみに、仮に 個、つまり1兆個のUUIDv4を生成したとしても、
衝突確率は近似的に 程度です。
これを見ても、理論上のUUIDv4はかなり強力だと分かりますね。
現場で理論より早く衝突したら何を疑うべき?
ここが実務ではかなり大事です。
もし現場で「UUIDが思ったより早く衝突した」という話が出てきたら、UUIDv4の数学を疑うよりも先に、
実装側の乱数品質やUUIDの扱い方 を疑うべきです。
代表的な原因を見ていきましょう。
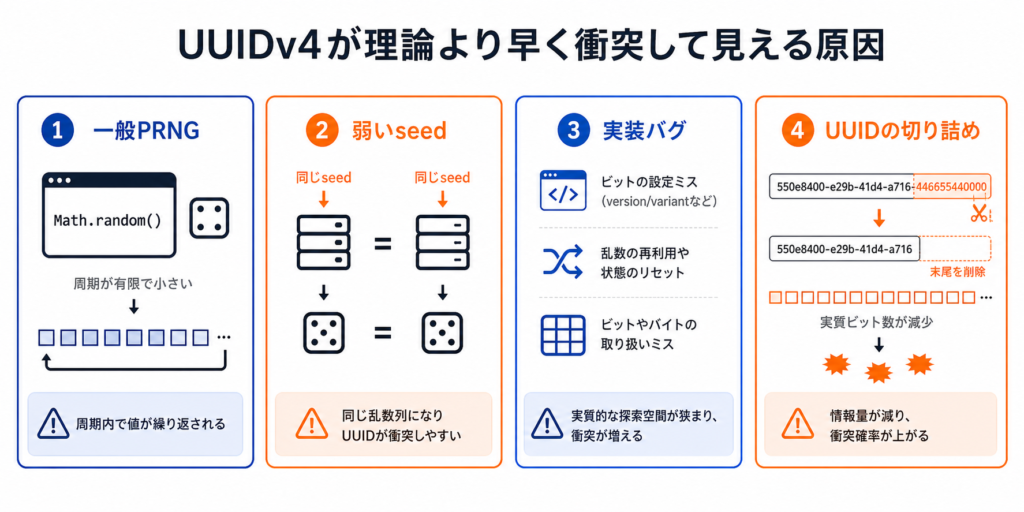
原因1. そもそもCSPRNGを使っていない
UUIDv4で期待されているのは、122bitの高品質なランダム性です。
ところが自作実装や軽量ライブラリでは、
暗号用途に耐える乱数ではなく、一般用途の疑似乱数を使ってしまうことがあります。
例えばJavaScriptの Math.random() は、MDNでも
「暗号学的に安全な乱数ではない」と明記されています。
またPythonの `random` モジュールは Mersenne Twister ベースで、
高速ですが決定的な疑似乱数です。
つまり、次のような自前実装はUUIDv4っぽく見えても危険です。
const value = Math.floor(Math.random() * 16);import random
value = random.getrandbits(128)これらは「見た目はランダム」でも、
内部状態が予測可能だったり、実効的な乱数空間が理論より小さくなったりします。
そのため、衝突確率が想定より大きくなる可能性があります。
なお、ここで言う「疑似乱数がダメ」という意味ではありません。
`crypto.randomUUID()` や `UUID.randomUUID()` のように、
暗号学的に安全な疑似乱数生成器(CSPRNG)を使っていれば問題ありません。
使いたいAPIの例
- ブラウザJavaScriptなら crypto.randomUUID()
- Node.jsなら
crypto.randomUUID() - Javaなら UUID.randomUUID()
- Pythonなら uuid.uuid4()
このあたりの標準APIは、少なくとも「UUIDを自作する」よりずっと安全です。
原因2. seedが弱い、または複数プロセスで同じ状態を引き継いでいる
疑似乱数は、初期状態である seed に依存して出力列が決まります。
そのため、もし複数のプロセスやサーバが
- 時刻だけをもとにseedしている
- PIDのような情報しか混ぜていない
- コンテナの複製やVMスナップショットから同じ乱数状態で起動している
- fork後にPRNG状態を共有している
といった状況だと、別インスタンスなのに同じ乱数列を吐くことがあります。
この場合、理論上は 通りあるはずでも、
実際にははるかに狭い空間で同じ値を回していることになってしまいます。
つまり、UUIDの衝突というより
乱数生成器の初期化ミス が本質的な原因ですね。
原因3. OSやライブラリの乱数実装に不具合がある
これは頻度こそ高くないですが、実例があります。
有名なのが Debian 系の OpenSSL で発生した「予測可能な乱数生成器」の問題です。
https://lists.debian.org/debian-security-announce/2008/msg00152.html
https://security-tracker.debian.org/tracker/CVE-2008-0166
この不具合では、乱数のエントロピーが大きく損なわれ、
生成される鍵が推測可能になってしまいました。
UUIDv4の理論が弱いのではなく、下で動いている乱数供給元が壊れると全体が壊れる
ということです。
普段は標準ライブラリを使っていれば十分ですが、
もし特定環境で大量の重複が見つかった場合には、
- 利用している言語ランタイムのバージョン
- 乱数生成APIの実装
- OSやコンテナ基盤
- セキュリティアドバイザリ
まで確認したほうが良いでしょう。
原因4. UUIDが衝突したのではなく、途中で切り詰めている
実務ではこれもかなりあります。例えばUUID文字列全体を保存せずに、
- 先頭8文字だけ使う
- 一部だけ短縮IDとして使う
- DBのカラム長不足で欠ける
- 表示用IDと内部IDを混同する
といったことをしてしまうと、当然ながら衝突確率は一気に上がります。
先頭8文字だけ使うなら、実質32bitしか使っていないのと同じです。
この時点で、もはや UUIDv4 の122bitランダムという前提は崩れています。
「UUIDが衝突した」と報告されたときは、
まず本当に フルのUUIDv4をそのまま比較しているのかを確認したいですね。
UUIDv4の衝突はどれくらい心配すべき?
結論として、標準的で信頼できる実装を使っている限り、UUIDv4の衝突はまず問題になりません。
誕生日のパラドックスを考慮しても、
衝突確率が現実的な水準に上がってくるのは オーダーです。
通常のWebサービスや業務システムでは、そこまで到達することはまずないでしょう。
一方で、理論より早く重複が見えたときは、
- 弱い疑似乱数を使っていないか
- 自作実装になっていないか
- seedの扱いが雑ではないか
- UUIDを途中で短縮していないか
を疑うべきです。つまり、UUIDv4で本当に怖いのは
「数学上の衝突確率」よりも
「実装ミスによってランダム性を自分で削ってしまうこと」
のほうだと言えますね。
UUIDv7のすすめ
最近は UUIDv4 だけでなく、UUIDv7 もかなり注目されています。
UUIDv7 は 2024年5月に公開された RFC 9562 で標準化された形式で、
Unix 時間ベースの並びやすい構造を持っているのが特徴です。
UUIDv4 はランダム性が高く、単純に一意なIDを配りたいときに扱いやすいです。
一方で UUIDv7 は、時系列順にソートしやすい ので、
データベースのインデックス局所性やログの追跡しやすさを重視する場面で選ばれやすくなっています。
UUIDは便利ですが、便利だからこそ中身を雑に扱わないことが大切です。
これからUUIDを採番に使う方の参考になれば嬉しいです!
UUIDv4の衝突テストサイト
UUIDv4が本当に衝突するのか、実際にひたすらUUIDを生成してテストするサイトを作りました。

この記事が役に立ちましたらぜひ左下のGoodボタンをお願いします!
皆様のGoodが執筆の励みになります。

コメント